Predicting Porosity Defects in Die Casting: A Machine Learning Breakthrough for Zero-Defect Production
This technical summary is based on the academic paper "Factors Analysis and Prediction in Die-casting Process for Defects Reduction" by Pavee Siriruk, Titiwetaya Yaikratok, published in Proceedings of the International Conference on Industrial Engineering and Operations Management (2022).
Keywords
- Primary Keyword: Die Casting Defect Prediction
- Secondary Keywords: Machine Learning in Die Casting, Porosity Defect, Predictive Maintenance, Process Parameter Optimization, Hard Disk Drive Components
Executive Summary
- The Challenge: Outer surface porosity defects in high-precision die-cast components, like those for Hard Disk Drives (HDDs), are difficult to detect at the manufacturing site, leading to quality issues downstream.
- The Method: Researchers applied three machine learning algorithms—Decision Tree (DT), Logistic Regression (LR), and Random Forest (RF)—to five months of real-time production data from 35 machine parameters to predict defect occurrence.
- The Key Breakthrough: The Decision Tree (DT) algorithm, despite a slightly lower overall accuracy, proved far superior in actually predicting defect occurrences, while identifying "pressure releasing" (Factor 26) as the single most critical process parameter.
- The Bottom Line: For imbalanced datasets typical in quality control, focusing on balanced performance metrics like G-mean over simple accuracy is crucial for building a predictive model that can reliably identify defects.
The Challenge: Why This Research Matters for HPDC Professionals
In the high-stakes world of digital storage and HDD component manufacturing, quality is non-negotiable. A critical and persistent challenge is the outer surface porosity defect in die-cast parts like motor baseplates. This type of defect is notoriously difficult to detect 100% at the supplier's facility due to inspection limitations. When these parts pass through to customer processes, they can cause significant quality issues, and the failure of an HDD at the end-user level can damage a manufacturer's reputation.
Traditional solutions, such as enhancing inspection methods, require huge capital investments that increase component costs—a price customers are often unwilling to absorb. This research bypasses the inspection problem by going straight to the source: the die-casting process itself. By analyzing the relationship between machine parameters and defect formation, the study aims to control and predict defects before they even occur, representing a major step toward a true Industry 4.0 approach to quality management.
The Approach: Unpacking the Methodology
To build a robust predictive model, the researchers collected comprehensive, real-time data from a prototype die-casting machine over a five-month period. This created a rich dataset representing the full scope of process variation.
- Data Collection: The study captured 35 distinct machine parameters for every single part produced, including mold temperatures, speeds, velocities, and pressures. Each part was serialized, allowing machine data to be precisely matched with its final inspection result (OK/NG). After data cleansing, 92,000 complete datasets were used for modeling.
- Defect Focus: While 17 types of casting defects were classified, the analysis focused exclusively on surface porosity, a defect caused by trapped gas bubbles during solidification.
- Modeling Techniques: Three supervised machine learning classification algorithms were trained and tested:
- Decision Trees (DT)
- Logistic Regression (LR)
- Random Forests (RF)
- Performance Evaluation: The models were evaluated using a Confusion Matrix to measure not just overall accuracy, but also Precision, Recall, F-Score, and the crucial G-mean, which indicates the balance of prediction performance for both good (major class) and defective (minor class) parts.
The Breakthrough: Key Findings & Data
The analysis yielded two critical breakthroughs: identifying the most influential process parameters and determining the most effective predictive algorithm for a real-world manufacturing environment.
Finding 1: Pressure Releasing is the Most Critical Factor for Porosity
Using a Feature Importance analysis, the study pinpointed the specific machine parameters that have the highest correlation with the formation of porosity defects. This provides a clear roadmap for process optimization.
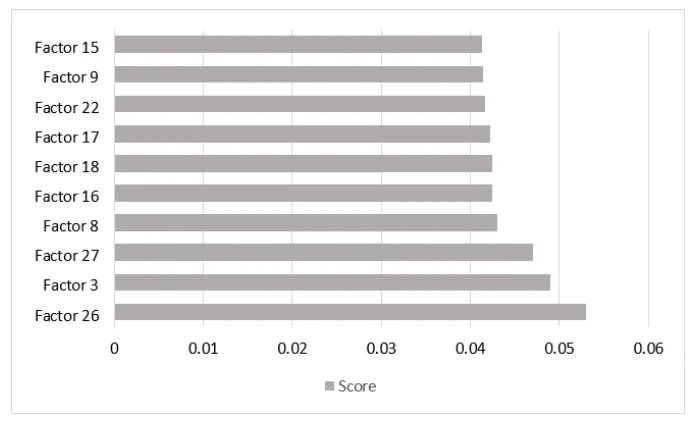
As shown in Table 2, the top five most influential factors were:
- Factor 26 (pressure releasing factor): Score of 0.053
- Factor 3: Score of 0.049
- Factor 27: Score of 0.047
- Factor 8: Score of 0.043
- Factor 16: Score of 0.042
This data strongly indicates that parameters related to pressure control during and after injection are the most critical levers for reducing porosity defects.
Finding 2: Decision Tree Outperforms in Real-World Defect Prediction
While Logistic Regression (LR) and Random Forest (RF) initially appeared superior with 95.85% accuracy, a deeper look revealed a fatal flaw. As shown in the confusion matrices (Figure 5 and Figure 6), both models predicted zero defects. They achieved high accuracy simply by classifying every part as "OK."
In contrast, the Decision Tree (DT) model, with a 91.18% accuracy, successfully identified 28 actual defect cases (Figure 4). This superiority is quantified by the G-mean value from Table 3, where DT achieved a score of 0.28, while LR and RF scored 0.00. A G-mean of 0.00 signifies a complete failure to predict the minority class (defects), making the model useless for quality control. The DT model, however, demonstrated a balanced ability to predict both "OK" and "NG" parts, making it the only viable solution.
Practical Implications for R&D and Operations
- For Process Engineers: This study suggests that adjusting Factor 26 (Pressure releasing related), Factor 3 (High-speed related), and Factor 27 (Pressure releasing related) may contribute significantly to reducing outer surface porosity. These parameters should be the primary focus for process control and optimization efforts.
- For Quality Control Teams: The data in Table 3 illustrates that relying on overall accuracy as a sole performance metric can be highly misleading for imbalanced datasets (where defects are rare). The G-mean is a far more reliable indicator of a model's ability to actually find the defects you are looking for.
- For Design Engineers: The paper's background notes that factors like "runner inadequate" can cause porosity. The findings that pressure and high-speed parameters are highly sensitive suggest that part and mold design should facilitate smooth metal flow and effective gas venting to minimize reliance on extreme process parameters.
Paper Details
Factors Analysis and Prediction in Die-casting Process for Defects Reduction
1. Overview:
- Title: Factors Analysis and Prediction in Die-casting Process for Defects Reduction
- Author: Pavee Siriruk, Titiwetaya Yaikratok
- Year of publication: 2022
- Journal/academic society of publication: Proceedings of the International Conference on Industrial Engineering and Operations Management
- Keywords: Big Data Analytics, Classification, Defects Prediction, Machine Learning, Predictive Maintenance.
2. Abstract:
Defect reduction has always been the continuous improvement topic that is being addressed in the manufacturing industry. Even nowadays, that the world is moving into the industrial 4.0, such a particular topic still has never outdated, only the new approaches have been introduced for the better achievement of defect reduction. This research aims to reduce the defects in die-casting process of the Hard Disk Drive (HDD) component manufacturing company, focusing on the effects of various machine parameters on the defects occurring in casting products. Predictive maintenance approach and machine learning have been introduced to determine the suitable data modelling technique. The most related independent factors can be identified through Feature Importance method. Decision Tree (DT) performed the best results among other classification methods. The 91.18% accuracy can be obtained by decision tree algorithm. However, the ratio of labelled data still needs to be reviewed and optimized for the future work as well as continue the actual checking on the frontline production results with the Subject-Matter Expert (SME) also required in order to obtain the best prediction results.
3. Introduction:
Predictive maintenance (PdM) is widely used to reduce downtime, improve productivity, and reduce waste. This research focuses on die-casting for motor baseplates in the Hard Disk Drive (HDD) industry, specifically targeting outer surface porosity defects. This defect is often missed during manufacturer inspection but found by the customer, causing significant quality issues. The high risk of HDD failure makes this a critical issue. Two scenarios have been proposed to solve this: 1) improve inspection methods, which is a costly investment, or 2) use multi-level production data analytics to find the relationship between machine parameters and defects. This study pursues the second scenario, exploring how to utilize machine data to control defect occurrence, a key challenge for suppliers moving towards Industry 4.0.
4. Summary of the study:
Background of the research topic:
The study addresses the persistent problem of defect reduction in the manufacturing industry, specifically within the die-casting process for HDD components. It leverages Industry 4.0 concepts like predictive maintenance and machine learning to tackle this issue.
Status of previous research:
Previous research has applied various machine learning algorithms like Partial Least Squares Regression (PLSR), Artificial Neural Network (ANN), and Random Forests (RFs) for predictive maintenance in different industries. Studies have shown success in predicting failures in steel manufacturing, wind turbines, and other industrial assets. Specifically for die-casting, a 2020 study by Kim Ji Soo et al. achieved over 89% prediction accuracy using process condition data. This paper builds on that foundation by comparing multiple classification models for a specific, hard-to-detect defect.
Purpose of the study:
The research aims to reduce defects in the die-casting process of an HDD component manufacturer by identifying the machine parameters that cause porosity defects and determining the most suitable machine learning model for predicting their occurrence.
Core study:
The core of the study involves collecting real-time data from 35 machine sensor attributes over five months, matching this data with final product quality (OK/NG for porosity), and then training and evaluating three classification models (Decision Tree, Logistic Regression, Random Forest) to find the best predictor of defects.
5. Research Methodology
Research Design:
The study employed a quantitative research design using real production data. It followed a standard machine learning framework: data collection, data pre-processing, model selection and training, and performance evaluation.
Data Collection and Analysis Methods:
- Data Collection: Two data groups were collected: 1) real-time machine data from sensors for 35 parameters, and 2) visual inspection data classifying parts as OK or NG for porosity. The two datasets were matched via serial number. An initial 141,000 data sets were collected, with 92,000 remaining after cleaning.
- Analysis Methods: Feature Importance analysis (using Extra Tree Classifier) was used to identify the most influential parameters. The performance of Decision Tree, Logistic Regression, and Random Forest models was evaluated using a Confusion Matrix and metrics including Accuracy, Precision, Recall, F-Score, and G-mean.
Research Topics and Scope:
The research is focused on a single defect type (outer surface porosity) in the die-casting process for a specific component (HDD motor baseplate) from a single prototype machine.
6. Key Results:
Key Results:
- Feature importance analysis identified Factor 26 (pressure releasing factor) as the most significant contributor to porosity defects, with a score of 0.053.
- Logistic Regression (LR) and Random Forest (RF) models achieved 95.85% accuracy but failed to predict any defects, resulting in a G-mean of 0.00.
- The Decision Tree (DT) model achieved 91.18% accuracy but successfully predicted both OK and NG parts, resulting in a superior G-mean of 0.28, making it the most effective model for this application.
Figure Name List:
- Figure. 1 General framework of machine learning
- Figure 2. Confusion matrix
- Figure. 3 Comparing score of feature importance analysis results
- Figure. 4 Confusion Metrix of DT
- Figure. 5 Confusion Metrix of LR
- Figure. 6 Confusion Metrix of RF
7. Conclusion:
The study successfully identified the most critical factors affecting porosity defects in die-cast products, with Factor 26 (Pressure releasing related) being the most significant. The Decision Trees (DT) algorithm performed the best in predicting these defects, achieving 91.18% accuracy and, more importantly, demonstrating a balanced predictive capability (G-Mean of 0.28) for the imbalanced dataset. The authors note that future work should focus on optimizing the imbalanced dataset and continuing to validate model predictions with subject-matter experts on the production floor to create the most robust predictive model for real-world practice.
8. References:
- Aliyan E., Aghamohammadi M., Kia M., Heidari A., Shafie-khah, M., & Catalão J. P., Decision tree analysis to identify harmful contingencies and estimate blackout indices for predicting system vulnerability. Electric Power Systems Research, 178, 106036, 2020.
- Amihai I., Gitzel R., Kotriwala A. M., Pareschi D., Subbiah S., & Sosale G., An industrial case study using vibration data and machine learning to predict asset health. In 2018 IEEE 20th Conference on Business Informatics (CBI) vol. 1, pp. 178-185, IEEE, July 2018.
- Behera S., Choubey A., Kanani C. S., Patel Y. S., Misra R., & Sillitti A., Ensemble trees learning based improved predictive maintenance using IIoT for turbofan engines, In Proceedings of the 34th ACM/SIGAPP Symposium on pplied Computing, pp. 842-850, April 2019.
- Bukhsh Z. A., Saeed A., Stipanovic I., & Doree A. G., Predictive maintenance using tree-based classification techniques: A case of railway switches, Transportation Research Part C: Emerging Technologies, vol.101, pp. 35-54, 2019.
- Canizo M., Onieva E., Conde A., Charramendieta S., & Trujillo S., Real-time predictive maintenance for wind turbines using Big Data frameworks, In 2017 ieee international conference on prognostics and health management (icphm), pp. 70-77, IEEE, June 2017.
- Carvalho T. P., Soares F. A., Vita, R., Francisco R. D. P., Basto J. P., & Alcalá S. G., A systematic literature review of machine learning methods applied to predictive maintenance. Computers & Industrial Engineering, 137, 106024, 2019.
- Chen X., Van Hillegersberg J., Topan E., Smith S. & Roberts M., Application of data-driven models to predictive maintenance: Bearing wear prediction at TATA steel, Expert Systems with Applications, 186, 115699, 2021.
- Durbhaka Gopi Krishna, and Barani Selvaraj, Predictive maintenance for wind turbine diagnostics using vibration signal analysis based on collaborative recommendation approach, 2016 International Conference on Advances in Computing, Communications and Informatics (ICACCI), IEEE, 2016.
- Hsu J. Y., Wang Y. F., Lin K. C., Chen M. Y., & Hsu J. H. Y., Wind turbine fault diagnosis and predictive maintenance through statistical process control and machine learning. Ieee Access, vol. 8, 23427-23439, 2020.
- Kaparthi, Shashidhar, and Daniel Bumblauskas, Designing predictive maintenance systems using decision tree-based machine learning techniques, International Journal of Quality & Reliability, Management, 2020.
- Kim Ji Soo, Jun Kim, and Ju Yeon Lee, Die-Casting Defect Prediction and Diagnosis System using Process Condition Data, Procedia Manufacturing, vol. 51, pp.359-364, 2020.
- Kolokas N., Vafeiadis T., Ioannidis D. & Tzovaras D, Forecasting faults of industrial equipment using machine learning classifiers, In 2018 Innovations in Intelligent Systems and Applications (INISTA), pp. 1-6, IEEE, July 2018.
- Lasisi, Ahmed and Nii Attoh-Okine, Principal components analysis and track quality index: A machine learning approach, Transportation Research Part C: Emerging Technologies, vol. 91, pp. 230-248, 2018.
- Liao Haitao, Wenbiao Zhao, and Huairui Guo, Predicting remaining useful life of an individual unit using proportional hazards model and logistic regression model, RAMS'06. Annual Reliability and Maintainability Symposium, 2006, IEEE, 2006.
- Wu Z., Lin W., Zhang Z., Wen A., & Lin L., An ensemble random forest algorithm for insurance big data analysis. In 2017 IEEE International Conference on Computational Science and Engineering (CSE) and IEEE International Conference on Embedded and Ubiquitous Computing (EUC), vol. 1, pp. 531-536, July 2017.
- Mathew V., Toby T., Singh V., Rao B. M., & Kumar M. G., Prediction of Remaining Useful Lifetime (RUL) of turbofan engine using machine learning. In 2017 IEEE International Conference on Circuits and Systems (ICCS), pp. 306-311, IEEE, December 2017.
- Nourian-Avval, Ahmad, and Ali Fatemi., Fatigue life prediction of cast aluminum alloy based on porosity characteristics, Theoretical and Applied Fracture Mechanics 109: 102774, 2020.
- Park Sangwoo, Kim Changgyun, and Sekyoung Youm., Establishment of an IoT-based smart factory and data analysis model for the quality management of SMEs die-casting companies in Korea, International Journal of Distributed Sensor Networks 15.10, 1550147719879378, 2019.
- Phillips J., Cripps E., Lau J. W., & Hodkiewicz M. R., Classifying machinery condition using oil samples and binary logistic regression, Mechanical Systems and Signal Processing, vol.60, pp. 316-325, 2015.
- Prytz R., Nowaczyk S., Rögnvaldsson T., & Byttner S., Predicting the need for vehicle compressor repairs using maintenance records and logged vehicle data, Engineering applications of artificial intelligence, vol. 41, pp. 139-150, 2015.
- Rai R., Tiwari, M. K., Ivanov, D., & Dolgui, A., Machine learning in manufacturing and industry 4.0 applications, J. of Production Research, 2021.
- Rønsch G. Ø., Kulahci M., & Dybdahl M., An investigation of the utilisation of different data sources in manufacturing with application in injection moulding, International Journal of Production Research, pp. 1-18, 2021.
- Su C. J., & Huang S. F, Real-time big data analytics for hard disk drive predictive maintenance, Computers & Electrical Engineering, vol. 71, pp. 93-101, 2018.
- Zhang Zhongju, and Pengzhu Zhang, Seeing around the corner: an analytic approach for predictive maintenance using sensor data. "Journal of Management Analytics 2.4, pp. 333-350, 2015.
Expert Q&A: Your Top Questions Answered
Q1: Why did the research focus only on outer surface porosity and not other defect types?
A1: The paper's introduction highlights that this specific defect cannot be detected 100% at the manufacturer's site but causes significant quality issues for the customer (HDD manufacturer). This makes it a high-priority, high-impact problem to solve. By focusing on a single, critical defect, the study could develop a more targeted and effective predictive model.
Q2: The accuracy for Logistic Regression and Random Forest was 95.85%, higher than the Decision Tree's 91.18%. Why was the Decision Tree model chosen as the best?
A2: This is the most critical insight from the paper. As shown in Table 3, the G-mean for LR and RF was 0.00, meaning they completely failed to predict any actual defects. Their high accuracy came from correctly identifying the "OK" parts, which form the vast majority of the data. The Decision Tree model, with a G-mean of 0.28, demonstrated a balanced ability to identify both "OK" and "NG" parts, making it the only practically useful model for defect detection.
Q3: What specific machine parameters were identified as most critical to controlling porosity?
A3: The feature importance analysis in Table 2 clearly identified the top five most influential parameters. The most critical was Factor 26, described as a "pressure releasing factor." Factors 27 (also pressure releasing), 3 (high-speed related), 8 (high-speed related), and 16 (filling pressure related) were also highly significant. This suggests that managing pressure and speed profiles during and after injection is key to minimizing porosity.
Q4: How was the data for this study collected? Is it applicable to other machines?
A4: The data was collected over a 5-month period from a single prototype machine equipped with sensors to capture 35 process attributes for every part. While the specific model is tuned to this machine, the methodology is highly applicable elsewhere. The framework of collecting serialized process data, matching it with quality outcomes, and using machine learning to identify key parameters can be replicated on any modern die-casting machine.
Q5: The paper mentions an "imbalance dataset" as a concern. What does that mean and why is it important?
A5: An imbalanced dataset is one where one class (e.g., "OK" parts) vastly outnumbers the other class (e.g., "NG" parts). This is typical in quality control, where defects are rare. It's a major concern because many machine learning algorithms can achieve high accuracy by simply always predicting the majority class, as seen with the LR and RF models in this study. This is why specialized performance metrics like G-mean are essential to ensure the model is actually learning to identify the rare defect events.
Conclusion: Paving the Way for Higher Quality and Productivity
This research provides a powerful demonstration of how machine learning can solve persistent quality challenges in high-pressure die casting. By moving beyond simple accuracy metrics and focusing on a model's true predictive power for rare defects, the study offers a practical roadmap for Die Casting Defect Prediction. The identification of pressure and speed-related parameters as the root cause of porosity provides engineers with a clear target for process optimization. The success of the Decision Tree algorithm underscores the importance of selecting the right tool for the specific challenge of an imbalanced, real-world manufacturing dataset.
At CASTMAN, we are committed to applying the latest industry research to help our customers achieve higher productivity and quality. If the challenges discussed in this paper align with your operational goals, contact our engineering team to explore how these principles can be implemented in your components.
Copyright Information
- This content is a summary and analysis based on the paper "Factors Analysis and Prediction in Die-casting Process for Defects Reduction" by "Pavee Siriruk, Titiwetaya Yaikratok".
- Source: The paper was published in the Proceedings of the International Conference on Industrial Engineering and Operations Management, Istanbul, Turkey, March 7-10, 2022.
This material is for informational purposes only. Unauthorized commercial use is prohibited.
Copyright © 2025 CASTMAN. All rights reserved.