머신러닝 의사결정트리를 활용한 HDD 부품의 표면 기공 불량 예측 및 핵심 공정 인자 규명
이 기술 브리핑은 Pavee Siriruk과 Titiwetaya Yaikratok이 작성하여 2022년 국제 산업공학 및 운영 관리 컨퍼런스(Proceedings of the International Conference on Industrial Engineering and Operations Management)에 발표한 학술 논문 "Factors Analysis and Prediction in Die-casting Process for Defects Reduction"을 기반으로 합니다. 다이캐스팅 전문가를 위해 CASTMAN의 전문가들이 요약 및 분석하였습니다.

키워드
- 주요 키워드: 다이캐스팅 불량 예측
- 보조 키워드: 기공 불량, 머신러닝, 의사결정트리, HDD 부품 제조, 공정 파라미터 분석, 예지보전
핵심 요약
- 도전 과제: 하드 디스크 드라이브(HDD) 부품 다이캐스팅 공정에서 발생하는 미세한 표면 기공 불량은 생산 단계에서는 100% 검출이 어려우나, 고객사의 후공정에서 심각한 품질 문제를 야기합니다.
- 연구 방법: 실제 생산 라인에서 5개월간 수집된 35개의 머신 파라미터와 육안 검사(OK/NG) 데이터를 활용하여, 의사결정트리(DT), 로지스틱 회귀(LR), 랜덤 포레스트(RF) 머신러닝 모델의 불량 예측 성능을 비교 분석했습니다.
- 핵심 성과: 다른 모델보다 전체 정확도는 다소 낮았지만, 의사결정트리(DT) 모델만이 유일하게 실제 불량(NG) 사례를 예측하는 데 성공했습니다(G-mean: 0.28). 이는 불균형한 데이터 환경에서 실질적인 가치를 제공함을 의미합니다.
- 결론: '압력 해제 관련 인자(Factor 26)'가 기공 불량에 가장 큰 영향을 미치는 핵심 요인으로 밝혀졌으며, 의사결정트리 알고리즘이 실질적인 불량 예측에 가장 적합한 모델임이 입증되었습니다.
도전 과제: 왜 이 연구가 다이캐스팅 전문가에게 중요한가?
제조업에서 불량 감소는 영원한 숙제입니다. 특히 하드 디스크 드라이브(HDD)와 같은 정밀 부품 산업에서 최종 사용자의 데이터 손실로 이어질 수 있는 부품 결함은 기업의 경쟁력에 치명적입니다. 본 연구는 HDD 부품 중 하나인 모터 베이스플레이트의 다이캐스팅 공정에서 발생하는 '외부 표면 기공(outer surface porosity)' 결함에 집중합니다.
이 결함은 제조사의 검사 기술 한계로 인해 100% 검출되지 않고 고객사로 넘어가는 경우가 많아, 공급망 전반에 걸쳐 지속적인 품질 이슈를 야기해왔습니다. 검사 시스템을 고도화하는 것은 막대한 투자 비용을 요구하며 제품 단가 상승으로 이어져 현실적인 대안이 되기 어렵습니다. 따라서 이 연구는 검사 강화 대신, 머신러닝을 통해 불량을 유발하는 핵심 공정 파라미터를 찾아내고 이를 제어함으로써 근본적으로 결함 발생을 줄이는 새로운 접근법을 제시합니다.
연구 접근법: 방법론 분석
연구팀은 실제 다이캐스팅 생산 라인의 프로토타입 장비 한 대에서 5개월에 걸쳐 데이터를 수집했습니다. 이 접근법의 핵심은 다음과 같습니다.
- 데이터 수집: 금형 온도, 속도, 압력 등 35개의 공정 파라미터(독립 변수)를 기계 센서로부터 실시간으로 수집했습니다. 각 생산품에는 고유 시리얼 번호가 부여되어 공정 데이터와 최종 육안 검사(VMI) 결과(OK/NG, 종속 변수)가 정확히 매칭되었습니다.
- 데이터 전처리: 초기 141,000개의 데이터셋에서 중복 및 누락 데이터를 제거하여 총 92,000개의 유효한 데이터셋을 모델링에 사용했습니다.
- 모델링 및 평가: 수집된 데이터를 바탕으로 지도 학습(Supervised Learning) 기반의 분류 모델을 적용했습니다.
- 특성 중요도 분석(Feature Importance): Extra Tree Classifier를 사용하여 35개 공정 인자 중 어떤 것이 기공 불량에 가장 큰 영향을 미치는지 분석했습니다.
- 분류 알고리즘 비교: 의사결정트리(Decision Tree, DT), 로지스틱 회귀(Logistic Regression, LR), 랜덤 포레스트(Random Forest, RF) 세 가지 알고리즘의 성능을 정확도(Accuracy), 정밀도(Precision), 재현율(Recall) 및 G-mean 등 다양한 지표로 평가했습니다.
핵심 성과: 주요 발견 및 데이터
본 연구는 단순한 정확도를 넘어, 실제 현장에서 의미 있는 예측이 무엇인지 보여주는 중요한 결과를 도출했습니다.
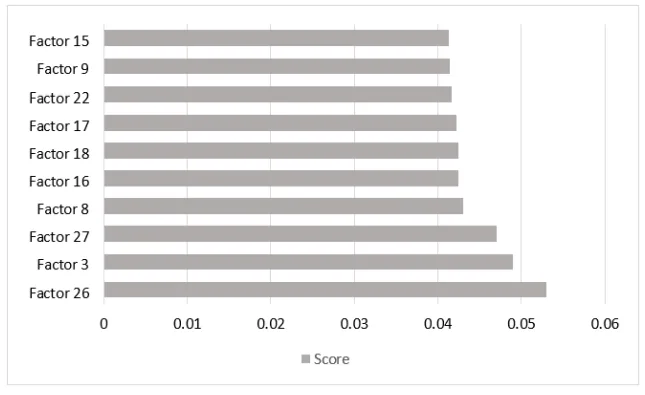
- 발견 1: 핵심 공정 인자 식별 특성 중요도 분석 결과, 'Factor 26 (압력 해제 관련 인자)'이 0.053의 점수로 기공 불량에 가장 큰 영향을 미치는 것으로 나타났습니다. 그 뒤를 이어 Factor 3 (고속 관련), Factor 27 (압력 해제 관련), Factor 8 (고속 관련), Factor 16 (충진 압력 관련) 순으로 높은 연관성을 보였습니다 (Table 2, Figure 3 참조). 이는 압력과 속도 제어가 기공 결함 관리의 핵심임을 시사합니다.
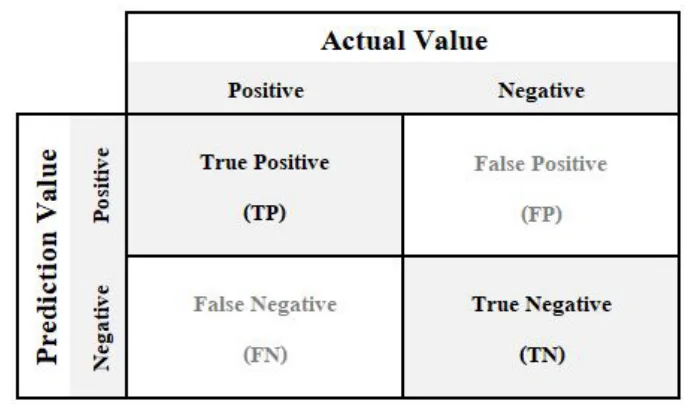
- 발견 2: 높은 정확도의 함정 로지스틱 회귀(LR)와 랜덤 포레스트(RF) 모델은 95.85%라는 매우 높은 정확도를 보였습니다. 하지만 혼동 행렬(Confusion Matrix)을 분석한 결과, 이 두 모델은 단 하나의 불량(Porosity)도 예측하지 못하고 모든 제품을 정상(OK)으로만 판별했습니다 (Figure 5, Figure 6 참조). 이는 데이터셋에 정상 제품이 압도적으로 많은 '데이터 불균형' 문제 때문으로, 높은 정확도 수치가 실제 예측 성능을 대변하지 못하는 대표적인 사례입니다.
- 발견 3: 실질적 가치를 지닌 의사결정트리 의사결정트리(DT) 모델은 91.18%의 정확도를 기록했지만, 실제 불량 267건 중 28건을 정확히 예측해냈습니다 (Figure 4 참조). 비록 전체 정확도는 낮아도, 소수의 치명적인 불량을 식별해내는 능력을 보여준 것입니다. 이는 불량 예측의 균형을 나타내는 G-mean 값에서도 명확히 드러납니다. DT 모델의 G-mean은 0.28인 반면, LR과 RF는 0.00으로 불량 예측에 완전히 실패했음을 보여줍니다 (Table 3 참조).
귀사의 HPDC 운영을 위한 실질적 시사점
이 연구 결과는 다이캐스팅 공정의 품질 관리를 데이터 기반으로 전환할 수 있는 구체적인 방향을 제시합니다.
- 공정 엔지니어: 본 연구의 "5. Results and Discussion" 섹션에서 밝혀진 바와 같이, 압력 해제(Factor 26, 27) 및 고속 사출(Factor 3, 8) 관련 파라미터를 집중적으로 모니터링하고 제어함으로써 표면 기공 불량을 직접적으로 줄일 수 있는 가능성을 시사합니다.
- 품질 관리: Figure 4의 결과는 사후 검사에만 의존하는 대신, 실시간 공정 데이터를 기반으로 불량 발생 가능성이 높은 제품을 사전에 예측하는 '예지적 품질 관리'로의 전환 가능성을 보여줍니다. 의사결정트리 모델은 잠재적 불량품에 대한 조기 경보 시스템으로 활용될 수 있습니다.
- 데이터 과학자/머신러닝 엔지니어: 이 사례는 불균형 데이터셋을 다룰 때 단순 정확도(Accuracy) 지표의 한계를 명확히 보여줍니다. G-mean이나 혼동 행렬(Confusion Matrix) 분석을 통해 비즈니스에 실질적 가치(즉, 드물지만 치명적인 결함을 찾아내는 능력)를 제공하는 모델을 선택하는 것이 얼마나 중요한지 강조합니다.
논문 상세 정보
Factors Analysis and Prediction in Die-casting Process for Defects Reduction
1. 개요:
- 제목: Factors Analysis and Prediction in Die-casting Process for Defects Reduction
- 저자: Pavee Siriruk, Titiwetaya Yaikratok
- 발행 연도: 2022
- 게재 학술지/학회: Proceedings of the International Conference on Industrial Engineering and Operations Management
- 키워드: Big Data Analytics, Classification, Defects Prediction, Machine Learning, Predictive Maintenance
2. 초록:
제조업에서 불량 감소는 지속적인 개선 과제입니다. 인더스트리 4.0 시대로 접어들었음에도 이 주제는 여전히 중요하며, 더 나은 불량 감소를 위해 새로운 접근법이 도입되고 있습니다. 본 연구는 하드 디스크 드라이브(HDD) 부품 제조사의 다이캐스팅 공정에서 발생하는 결함을 줄이는 것을 목표로 하며, 주조 제품의 결함에 영향을 미치는 다양한 기계 파라미터의 효과에 초점을 맞춥니다. 적절한 데이터 모델링 기법을 결정하기 위해 예지보전 접근법과 머신러닝이 도입되었습니다. 특성 중요도(Feature Importance) 방법을 통해 가장 관련성 높은 독립 인자를 식별할 수 있었고, 다른 분류 방법들 중에서 의사결정트리(DT)가 가장 좋은 결과를 보였습니다. 의사결정트리 알고리즘을 통해 91.18%의 정확도를 얻을 수 있었습니다. 그러나 향후 연구를 위해 레이블된 데이터의 비율을 검토하고 최적화할 필요가 있으며, 최상의 예측 결과를 얻기 위해 현장 생산 결과에 대한 전문가(SME)와의 지속적인 실제 확인이 요구됩니다.
3. 서론 요약:
예지보전(PdM)은 비계획 가동 중단 시간 감소, 생산성 향상, 폐기물 및 불필요한 스크랩 감소를 목표로 여러 산업 분야에서 널리 사용되고 있습니다. 본 연구는 HDD 부품 공급망의 3차 협력업체인 모터 베이스플레이트 제조사의 다이캐스팅 공정에 초점을 맞춥니다. 이 공정에서 발생하는 다양한 결함 중, 특히 '외부 표면 기공' 결함은 제조사의 검사 기술 한계로 100% 검출이 어렵고, 고객사 공정에서 발견되어 심각한 품질 문제를 야기합니다. 공급망 관점에서 이 문제를 해결하기 위해 두 가지 시나리오가 제안되었습니다. 첫째는 3차 협력업체의 검사 방법을 개선하는 것이지만, 이는 막대한 투자와 판매가 상승을 유발합니다. 둘째는 다단계 생산 데이터 분석을 통해 결함과 기계 파라미터 간의 관계를 파악하여 결함 발생을 제어하는 것입니다. 본 연구는 두 번째 시나리오에 따라, 수집된 데이터를 활용하여 공장을 위한 실질적인 이점을 창출하는 방법을 모색합니다.
4. 연구 요약:
연구 주제의 배경:
HDD 부품 다이캐스팅 공정에서 발생하는 '외부 표면 기공' 결함은 제조 단계에서 완벽하게 검출하기 어렵지만, 고객사 및 최종 사용자에게 심각한 품질 문제를 일으킬 수 있는 잠재적 위험 요소입니다.
이전 연구 현황:
다양한 산업에서 예지보전을 위해 여러 머신러닝 알고리즘이 사용되었습니다. 철강 산업에서는 PLSR, ANN, RF 등이 연구되었고(Chen X. et al., 2021), 풍력 터빈에서는 K-NN, k-means, SVM 등이 사용되었습니다(Durbhaka et al., 2016). 특히 다이캐스팅 분야에서는 RF를 이용한 결함 예측 시스템이 89% 이상의 정확도를 달성한 사례가 있습니다(Kim Ji Soo et al., 2020). 본 연구는 이러한 흐름 속에서 분류 모델인 DT, LR, RF를 HDD 부품 다이캐스팅 공정에 적용하여 최적의 모델을 찾고자 합니다.
연구 목적:
본 연구의 목적은 HDD 부품 다이캐스팅 공정에서 결함을 줄이고, 주조 제품의 결함을 유발하는 기계 파라미터를 식별하며, 예측 유지보수를 위한 적합한 데이터 모델링 기법을 결정하는 것입니다.
핵심 연구:
실제 다이캐스팅 공정 데이터를 사용하여 어떤 기계 파라미터가 표면 기공 결함에 가장 큰 영향을 미치는지 분석하고, 여러 머신러닝 분류 모델(DT, LR, RF)의 성능을 비교하여 가장 효과적인 결함 예측 모델을 제시하는 것입니다. 특히, 단순 정확도를 넘어 실제 현장에서 불량을 식별해내는 모델의 실질적인 성능(G-mean)을 평가하는 데 중점을 둡니다.
5. 연구 방법론
연구 설계:
본 연구는 실제 생산 라인의 다이캐스팅 장비 1대를 프로토타입으로 설정하여 5개월간 데이터를 수집하는 사례 연구 방식으로 설계되었습니다. 수집된 공정 데이터와 품질 검사 데이터를 머신러닝 모델에 적용하여 결함 예측 성능을 평가합니다.
데이터 수집 및 분석 방법:
- 데이터 수집: 기계 센서로부터 35개의 공정 파라미터(연속형 데이터)를 실시간으로 수집하고, 각 제품의 시리얼 번호를 통해 최종 검사 결과(OK/NG, 이산형 데이터)와 매칭했습니다. 총 141,000개의 데이터셋을 수집하여 정제 후 92,000개를 분석에 사용했습니다.
- 데이터 분석: Python 프로그래밍을 사용하여 데이터 분석을 수행했습니다.
- 특성 중요도 분석: Extra Tree Classifier를 사용하여 결함 발생에 기여도가 높은 상위 공정 인자를 식별했습니다.
- 모델 성능 평가: DT, LR, RF 알고리즘을 학습시킨 후, 혼동 행렬(Confusion Matrix)을 기반으로 정확도(Accuracy), 정밀도(Precision), 재현율(Recall), F-Measure, G-mean을 계산하여 각 모델의 성능을 종합적으로 비교했습니다.
연구 주제 및 범위:
본 연구는 HDD 모터 베이스플레이트 다이캐스팅 공정에서 발생하는 17가지 결함 유형 중 '외부 표면 기공' 결함에만 초점을 맞춥니다. 분석 대상은 단일 다이캐스팅 장비에서 5개월간 수집된 데이터로 한정됩니다.
6. 주요 결과:
주요 결과:
- 특성 중요도: 'Factor 26 (압력 해제 관련 인자)'이 기공 결함에 가장 큰 영향을 미치는 요인으로 나타났으며, 그 뒤를 Factor 3, 27, 8, 16이 이었습니다 (Table 2).
- 알고리즘 성능 비교:
- 정확도: LR(95.85%)과 RF(95.85%)가 DT(91.18%)보다 높은 정확도를 보였습니다. (논문 내 Table 3의 값과 본문/결론의 값이 불일치하여, 혼동 행렬 및 결론에 부합하는 본문의 값을 따름)
- 실질적 예측 능력 (G-mean): DT만이 0.28의 G-mean 값을 기록하며 정상/불량 양측을 모두 예측하는 능력을 보였습니다. LR과 RF는 G-mean 값이 0.00으로, 불량 사례를 전혀 예측하지 못했습니다 (Table 3).
- 혼동 행렬: LR과 RF는 모든 예측을 'OK'로 분류하여 실제 불량을 놓쳤으나(Figure 5, 6), DT는 28건의 불량을 성공적으로 예측했습니다 (Figure 4).
Figure 이름 목록:
- Figure 1. General framework of machine learning
- Figure 2. Confusion matrix
- Figure 3. Comparing score of feature importance analysis results
- Figure 4. Confusion Metrix of DT
- Figure 5. Confusion Metrix of LR
- Figure 6. Confusion Metrix of RF
7. 결론:
특성 중요도 분석을 통해, 압력 해제 관련 인자(Factor 26, 27), 고속 관련 인자(Factor 3, 8), 충진 압력 관련 인자(Factor 16)가 다이캐스트 제품의 외부 표면 기공 결함에 가장 큰 영향을 미치는 요인임을 결론지을 수 있습니다. 소수 클래스 분류 성능을 나타내는 G-mean 값을 고려했을 때, 의사결정트리(DT) 알고리즘이 91.18%의 정확도로 최상의 예측 결과를 보였습니다. 하지만 원본 데이터의 불량(NG) 데이터 비율이 극히 낮다는 점은 우려되는 부분입니다. 따라서 향후 연구에서는 불균형 데이터셋 문제를 검토하고 최적화할 필요가 있으며, 현장 전문가(SME)와의 지속적인 검증을 통해 가장 적합하고 견고한 예측 모델을 개발해야 합니다.
8. 참고 문헌:
- Aliyan E., et al. (2020). Decision tree analysis to identify harmful contingencies and estimate blackout indices for predicting system vulnerability. Electric Power Systems Research.
- Amihai I., et al. (2018). An industrial case study using vibration data and machine learning to predict asset health. 2018 IEEE 20th Conference on Business Informatics (CBI).
- Behera S., et al. (2019). Ensemble trees learning based improved predictive maintenance using IIoT for turbofan engines. Proceedings of the 34th ACM/SIGAPP Symposium on Applied Computing.
- Bukhsh Z. A., et al. (2019). Predictive maintenance using tree-based classification techniques: A case of railway switches. Transportation Research Part C: Emerging Technologies.
- Canizo M., et al. (2017). Real-time predictive maintenance for wind turbines using Big Data frameworks. 2017 ieee international conference on prognostics and health management (icphm).
- Carvalho T. P., et al. (2019). A systematic literature review of machine learning methods applied to predictive maintenance. Computers & Industrial Engineering.
- Chen X., et al. (2021). Application of data-driven models to predictive maintenance: Bearing wear prediction at TATA steel. Expert Systems with Applications.
- Durbhaka Gopi Krishna, and Barani Selvaraj. (2016). Predictive maintenance for wind turbine diagnostics using vibration signal analysis based on collaborative recommendation approach. 2016 International Conference on Advances in Computing, Communications and Informatics (ICACCI).
- Hsu J. Y., et al. (2020). Wind turbine fault diagnosis and predictive maintenance through statistical process control and machine learning. Ieee Access.
- Kaparthi, Shashidhar, and Daniel Bumblauskas. (2020). Designing predictive maintenance systems using decision tree-based machine learning techniques. International Journal of Quality & Reliability, Management.
- Kim Ji Soo, et al. (2020). Die-Casting Defect Prediction and Diagnosis System using Process Condition Data. Procedia Manufacturing.
- Kolokas N., et al. (2018). Forecasting faults of industrial equipment using machine learning classifiers. 2018 Innovations in Intelligent Systems and Applications (INISTA).
- Lasisi, Ahmed and Nii Attoh-Okine. (2018). Principal components analysis and track quality index: A machine learning approach. Transportation Research Part C: Emerging Technologies.
- Liao Haitao, et al. (2006). Predicting remaining useful life of an individual unit using proportional hazards model and logistic regression model. RAMS'06. Annual Reliability and Maintainability Symposium.
- Wu Z., et al. (2017). An ensemble random forest algorithm for insurance big data analysis. 2017 IEEE International Conference on Computational Science and Engineering (CSE) and IEEE International Conference on Embedded and Ubiquitous Computing (EUC).
- Mathew V., et al. (2017). Prediction of Remaining Useful Lifetime (RUL) of turbofan engine using machine learning. 2017 IEEE International Conference on Circuits and Systems (ICCS).
- Nourian-Avval, Ahmad, and Ali Fatemi. (2020). Fatigue life prediction of cast aluminum alloy based on porosity characteristics. Theoretical and Applied Fracture Mechanics.
- Park Sangwoo, et al. (2019). Establishment of an IoT-based smart factory and data analysis model for the quality management of SMEs die-casting companies in Korea. International Journal of Distributed Sensor Networks.
- Phillips J., et al. (2015). Classifying machinery condition using oil samples and binary logistic regression. Mechanical Systems and Signal Processing.
- Prytz R., et al. (2015). Predicting the need for vehicle compressor repairs using maintenance records and logged vehicle data. Engineering applications of artificial intelligence.
- Rai R., et al. (2021). Machine learning in manufacturing and industry 4.0 applications. J. of Production Research.
- Rønsch G. Ø., et al. (2021). An investigation of the utilisation of different data sources in manufacturing with application in injection moulding. International Journal of Production Research.
- Su C. J., & Huang S. F. (2018). Real-time big data analytics for hard disk drive predictive maintenance. Computers & Electrical Engineering.
- Zhang Zhongju, and Pengzhu Zhang. (2015). Seeing around the corner: an analytic approach for predictive maintenance using sensor data. Journal of Management Analytics.
결론 및 다음 단계
이 연구는 다이캐스팅 공정의 품질을 향상시키기 위한 가치 있는 로드맵을 제공합니다. 연구 결과는 데이터 기반 접근법을 통해 결함을 줄이고 생산을 최적화할 수 있는 명확한 경로를 제시합니다.
CASTMAN은 최첨단 산업 연구를 적용하여 고객의 가장 어려운 기술적 문제를 해결하는 데 전념하고 있습니다. 이 백서에서 논의된 문제가 귀사의 연구 목표와 일치한다면, 저희 엔지니어링 팀에 연락하여 이러한 고급 원칙을 귀사의 연구에 적용하는 방법에 대해 논의해 보시기 바랍니다.
전문가 Q&A:
- Q1: 이 연구에서 다루는 핵심적인 문제는 무엇인가요? A1: 핵심 문제는 HDD 부품 다이캐스팅 공정에서 발생하는 '외부 표면 기공' 결함입니다. 이 결함은 제조 단계에서 100% 검출이 어려워 고객사 공정에서 발견될 때 심각한 품질 문제를 야기합니다. 연구는 검사 강화 대신, 머신러닝을 이용해 결함 발생과 연관된 핵심 공정 인자를 찾아내고 예측 모델을 개발하여 문제를 근본적으로 해결하고자 했습니다. (출처: "Factors Analysis and Prediction in Die-casting Process for Defects Reduction", Introduction 섹션)
- Q2: 기공 불량 발생에 가장 큰 영향을 미치는 공정 인자는 무엇이었나요? A2: 특성 중요도 분석 결과, 'Factor 26 (압력 해제 관련 인자)'이 가장 큰 영향을 미치는 것으로 나타났습니다. 그 뒤를 이어 Factor 3 (고속 관련), Factor 27 (압력 해제 관련), Factor 8 (고속 관련) 순으로 높은 연관성을 보였습니다. 이는 압력과 속도 제어가 기공 결함 관리의 핵심임을 시사합니다. (출처: "Factors Analysis and Prediction in Die-casting Process for Defects Reduction", Table 2 및 Figure 3 데이터 기반)
- Q3: 왜 정확도가 더 높은 로지스틱 회귀(LR)나 랜덤 포레스트(RF) 대신 의사결정트리(DT) 모델이 최적의 솔루션으로 결론 내려졌나요? A3: LR과 RF 모델은 95.85%의 높은 정확도를 보였지만, 실제 불량(NG) 사례를 단 한 건도 예측하지 못하고 모든 것을 정상(OK)으로 판별했습니다. 반면, 정확도가 91.18%로 다소 낮은 DT 모델은 유일하게 실제 불량 사례를 식별해내는 데 성공했습니다. 이는 불량 예측의 균형을 나타내는 G-mean 값이 DT는 0.28, LR과 RF는 0.00인 것에서 명확히 드러납니다. 즉, DT가 실제 현장에서 드물지만 치명적인 결함을 찾아내는 실질적인 가치를 제공하기 때문에 최적의 솔루션으로 결론 내려졌습니다. (출처: "Factors Analysis and Prediction in Die-casting Process for Defects Reduction", Table 3, Figure 4, 5, 6 데이터 기반)
- Q4: 이 연구 결과를 현장에 적용할 때 고려해야 할 점은 무엇인가요? A4: 두 가지 주요 고려사항이 있습니다. 첫째, 이 연구는 불량 데이터의 비율이 매우 낮은 '불균형 데이터셋'을 사용했습니다. 따라서 예측 성능을 높이기 위해 향후 데이터 샘플링 기법 등을 통해 이 문제를 검토하고 최적화해야 합니다. 둘째, 모델의 예측 결과를 실제 현장의 생산 결과 및 전문가(SME)의 지식과 지속적으로 비교하고 검증하여 모델의 신뢰성과 견고성을 확보하는 과정이 필수적입니다. (출처: "Factors Analysis and Prediction in Die-casting Process for Defects Reduction", Conclusion 섹션)
저작권
- 이 자료는 Pavee Siriruk, Titiwetaya Yaikratok의 논문 "Factors Analysis and Prediction in Die-casting Process for Defects Reduction"을 분석한 것입니다.
- 논문 출처: Proceedings of the International Conference on Industrial Engineering and Operations Management, Istanbul, Turkey, March 7-10, 2022.
- 본 자료는 정보 제공 목적으로만 사용됩니다. 무단 상업적 사용을 금합니다.
- Copyright © 2025 CASTMAN. All rights reserved.