機械学習でポロシティ欠陥の根本原因を特定:決定木アルゴリズムが示す予測の可能性
この技術概要は、Pavee Siriruk氏およびTitiwetaya Yaikratok氏によって執筆され、「Proceedings of the International Conference on Industrial Engineering and Operations Management (2022)」で発表された学術論文「Factors Analysis and Prediction in Die-casting Process for Defects Reduction」に基づいています。ダイカスト製造の専門家のために、CASTMANのエキスパートが要約・分析しました。

キーワード
- 主要キーワード: ダイカスト 欠陥予測
- 副次キーワード: 機械学習, ポロシティ欠陥, HDD部品製造, 決定木, 要因分析, 予知保全
エグゼクティブサマリー
- 課題: HDD(ハードディスクドライブ)部品のダイカスト工程で発生する表面ポロシティ欠陥は、後工程で重大な品質問題を引き起こしますが、製造元での100%検出はコスト的に困難です。
- 手法: 5ヶ月間の実生産データ(35の機械パラメータ)と検査結果(OK/NG)を収集し、機械学習モデル(決定木、ロジスティック回帰、ランダムフォレスト)を用いて欠陥発生とパラメータの関係を分析しました。
- 重要な発見: 決定木(DT)アルゴリズムが、他のモデルでは不可能だった欠陥(NG)ケースの予測に成功。最も影響の大きいプロセス要因として「圧力解放関連の因子(Factor 26)」を特定しました。
- 結論: 本研究は、検査強化ではなく、プロセスパラメータの最適化によって欠陥を未然に防ぐアプローチの有効性を示唆しています。特に決定木モデルは、不均衡なデータセットにおいても実用的な洞察を提供します。
課題:なぜこの研究がダイカスト専門家にとって重要なのか
ダイカスト業界、特にHDD部品のような精密部品を製造する現場では、品質の一貫性が競争力の源泉です。本研究が焦点を当てる「外面ポロシティ欠陥」は、製造サプライヤー(3次請け)の段階では検査技術の限界から100%検出することが困難な、非常に厄介な問題です。この見逃された欠陥部品が顧客(HDDメーカー)の製造ラインに渡ると、最終製品の品質問題や、最悪の場合、エンドユーザーのデータ損失につながるHDD故障を引き起こす可能性があります(Su and Huang 2018)。
この問題に対し、サプライヤー側で検査体制を強化する案も検討されましたが、莫大な設備投資が必要となり、製品価格の上昇は避けられません。顧客がそのコスト増を受け入れる準備ができていない現状では、この解決策は非現実的です。そこで、本研究では「検査の強化」ではなく、「欠陥発生の根本原因の制御」に焦点を当てました。機械パラメータと欠陥発生の相関関係をデータ分析によって解明し、欠陥の発生自体を抑制する、よりスマートなアプローチを提案しています。
アプローチ:研究手法の解明
本研究では、この課題を解決するために、機械学習を用いた予知保全のアプローチを採用しました。
研究チームは、HDDモーターベースプレートを製造するダイカストマシン1台をプロトタイプとして選定し、5ヶ月間にわたる実生産データを収集しました。このデータには、金型温度、各種速度、圧力、タイムスタンプなど、35項目に及ぶ機械パラメータが含まれています。製造された各製品はシリアル番号で管理され、機械データと紐づけられました。
その後、製品は最終検査工程(VMIステーション)を通過し、良品(OK)か不良品(NG)かが記録されます。収集された141,000件のデータセットから、重複や欠損データを除去するデータクレンジングを行い、最終的に92,000件のクリーンなデータセットをモデル構築に使用しました。
分析には、以下の3つの主要な機械学習分類アルゴリズムが適用されました。
- 決定木(Decision Trees, DT)
- ロジスティック回帰(Logistic Regression, LR)
- ランダムフォレスト(Random Forests, RF)
さらに、どの機械パラメータが欠陥発生に最も寄与しているかを特定するために、特徴量の重要度(Feature Importance)分析も実施されました。
発見:主要な結果とデータ
分析の結果、ダイカストプロセスの品質改善に向けた、いくつかの重要な知見が得られました。
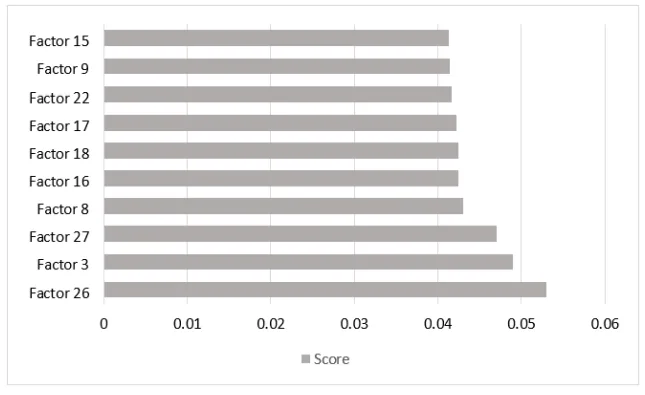
- 発見1:ポロシティ欠陥に最も影響を与える要因の特定 特徴量の重要度分析(Table 2, Figure 3)により、ポロシティ欠陥の発生に最も強く関連するパラメータが明らかになりました。「Factor 26(圧力解放関連の因子)」がスコア0.053で最も高い影響度を示し、次いでFactor 3(高速関連)、Factor 27(圧力解放関連)、Factor 8(高速関連)、Factor 16(充填圧力関連)が続きました。これは、圧力と速度の制御が品質に直結することを示唆しています。
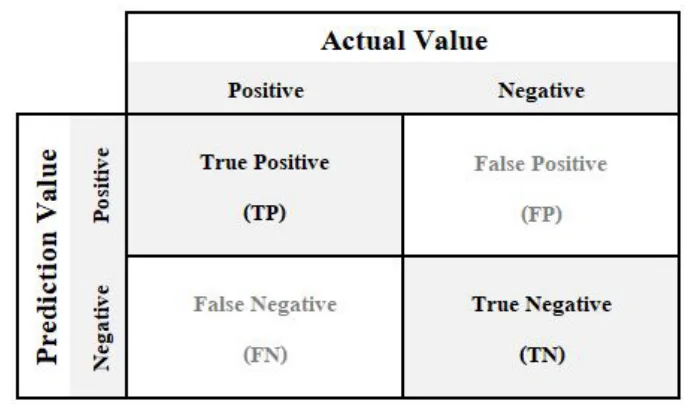
- 発見2:モデル性能の罠 - 「精度の高さ」が意味しないこと 各アルゴリズムの性能を比較したところ、ロジスティック回帰(LR)とランダムフォレスト(RF)は95.85%という非常に高い精度を示しました。しかし、これらのモデルのG-mean値(少数派クラスと多数派クラスの分類性能のバランスを示す指標)は0.00でした(Table 3)。これは、モデルが希少な「欠陥品(NG)」を一つも予測できず、すべてを「良品(OK)」と分類してしまったことを意味します(Figure 5, Figure 6)。つまり、精度の数値は高いものの、欠陥予測という目的においては全く機能していなかったのです。
- 発見3:決定木(DT)の実用的な優位性 一方、決定木(DT)モデルの精度は91.18%とわずかに低いものの、G-mean値は0.28を記録しました(Table 3)。これは、DTモデルが「良品(OK)」だけでなく、希少な「欠陥品(NG)」も予測できた唯一のモデルであることを示しています。実際に混同行列(Figure 4)を見ると、DTは28件の欠陥品を正しく「ポロシティあり」と予測することに成功しています。この結果は、不均衡なデータセットを扱う現実の製造現場において、DTが最も実用的な予測モデルであることを強く示唆しています。
ダイカスト工程への実践的な示唆
本研究の結果は、実際の製造現場におけるプロセス改善に直接的なヒントを与えます。
- プロセスエンジニアへ: 特徴量重要度分析の結果(Table 2)は、「Factor 26(圧力解放関連)」がポロシティ欠陥の最大の要因であることを示しています。これは、圧力解放のタイミングや速度プロファイルを微調整することが、欠陥削減の最も効果的な手段となりうることを意味します。
- 品質管理担当者へ: 本研究は、単に高い精度を目指すだけでは不十分であることを明確に示しました。特に、発生率は低いが致命的な欠陥を検出する場合、G-meanのような不均衡データを正しく評価できる指標が不可欠です。決定木モデルは、このような欠陥の早期警告システムの構築に向けた第一歩となり得ます。
- 金型設計・データサイエンティストへ: この研究は、機械学習を製造業に応用する際の実践的なケーススタディとなります。不均衡な問題に対して適切なアルゴリズム(この場合はLR/RFよりDT)を選択することの重要性を浮き彫りにしています。結論部で述べられているように、今後は不均衡データセットの取り扱い(オーバーサンプリングなど)を最適化し、少数派クラス(欠陥品)の予測精度をさらに向上させることが重要な課題です。
論文詳細
Factors Analysis and Prediction in Die-casting Process for Defects Reduction
1. 概要:
- 論文名: Factors Analysis and Prediction in Die-casting Process for Defects Reduction
- 著者: Pavee Siriruk, Titiwetaya Yaikratok
- 発表年: 2022
- 発表媒体: Proceedings of the International Conference on Industrial Engineering and Operations Management, Istanbul, Turkey, March 7-10, 2022
- キーワード: Big Data Analytics, Classification, Defects Prediction, Machine Learning, Predictive Maintenance.
2. 概要(Abstract):
欠陥削減は製造業における継続的な改善テーマである。インダストリアル4.0の時代においてもこのトピックは重要であり、より良い成果を達成するために新しいアプローチが導入されている。本研究は、HDD部品製造会社のダイカスト工程における欠陥削減を目的とし、鋳造製品に発生する欠陥に対する様々な機械パラメータの影響に焦点を当てる。予知保全アプローチと機械学習を導入し、適切なデータモデリング技術を決定した。特徴量の重要度手法により最も関連性の高い独立因子を特定でき、決定木(DT)が他の分類手法の中で最良の結果を示した。決定木アルゴリズムにより91.18%の精度が得られた。しかし、ラベル付きデータの比率は今後の作業で見直しと最適化が必要であり、最良の予測結果を得るためには、現場の生産結果を専門家(SME)と共に継続的に確認することも必要である。
3. 序論(Introduction):
予知保全(PdM)は、計画外のダウンタイム削減、生産性向上、無駄なスクラップの削減を目的として多くの産業で広く利用されている。本研究は、HDD業界の3次サプライヤーであるモーターベースプレート製造、特にダイカスト工程に焦点を当てる。ここで発生する外面ポロシティ欠陥は、製造元での検査技術の限界により100%検出できず、顧客の製造工程で品質問題を引き起こす。この問題に対し、サプライヤーでの検査方法を改善するシナリオはコスト増につながるため、欠陥と機械パラメータの関係を分析し、欠陥発生を制御する方法を見つけるという第2のシナリオが提案された。
4. 研究の要約:
研究トピックの背景:
HDD部品のダイカスト工程で発生する外面ポロシティ欠陥は、サプライヤー側で完全な検出が難しく、顧客側で品質問題を引き起こすという継続的な課題があった。コストをかけずにこの問題を解決するため、生産データ分析によるアプローチが求められていた。
従来の研究の状況:
予知保全の分野では、決定木(DT)、ロジスティック回帰(LR)、ランダムフォレスト(RF)など、様々な機械学習アルゴリズムが利用されてきた。DTは過学習のリスクがあるが、多くの産業で故障予測などに利用されている。LRは分類問題に用いられるが、他の手法ほど広くは使われていない。RFは多くの決定木を組み合わせるアンサンブル学習であり、高い精度を持つことから近年最も人気のあるアルゴリズムの一つである。
研究の目的:
本研究の目的は、HDD部品製造のダイカスト工程における欠陥を削減することである。特に、鋳造製品の欠陥を引き起こす機械パラメータを特定し、予知保全のための適切なデータモデリング技術を決定することを目指す。
研究の核心:
本研究の核心は、実際の生産データ(機械パラメータ)と検査データ(欠陥の有無)を組み合わせて機械学習モデルを構築し、どのパラメータが欠陥に影響を与え、どのモデルが最も効果的に欠陥を予測できるかを明らかにすることにある。特に、精度の高さだけでなく、実用的な予測能力(少数派である欠陥クラスの予測能力)を重視してモデルを評価した点に特徴がある。
5. 研究方法
研究デザイン:
プロトタイプのダイカストマシンから5ヶ月間にわたり35項目の機械パラメータデータを収集し、同期間に製造された製品の目視検査結果と紐づけた。
データ収集と分析方法:
機械センサーからのリアルタイムデータと、最終検査工程での欠陥分類データをシリアル番号を介して統合した。データクレンジング後、92,000件のデータセットを分析に使用。特徴量の重要度分析にはExtra Tree Classifierを用い、分類モデルとして決定木(DT)、ロジスティック回帰(LR)、ランダムフォレスト(RF)をPythonで実装し、性能を比較評価した。評価指標には精度(Accuracy)、G-mean、適合率(Precision)、再現率(Recall)、F値(F-Measure)を用いた。
研究の対象と範囲:
研究対象は、HDDモーターベースプレートのダイカスト工程で発生する17種類の欠陥のうち、「外面ポロシティ(surface porosity)」に限定している。データは1台の機械から収集されたものであり、その機械のプロセス変動を代表している。
6. 主要な結果:
主要な結果:
- 特徴量の重要度: Factor 26(圧力解放関連)が最も高いスコア(0.053)を示し、ポロシティ欠陥への影響が最も大きいことが示された(Table 2)。
- モデル性能: LRとRFは95.85%の高い精度を示したが、G-meanが0.00であり、欠陥品を全く予測できなかった。一方、DTは精度91.18%であったが、G-meanが0.28となり、欠陥品と良品の両方をある程度予測できる唯一のモデルであった(Table 3)。
- 混同行列: DTの混同行列(Figure 4)では、28件のポロシティ欠陥を正しく予測(True Positive)したのに対し、LR(Figure 5)とRF(Figure 6)の混同行列では、ポロシティ欠陥の予測数が0件であった。
図の名称リスト:
- Figure 1. General framework of machine learning
- Figure 2. Confusion matrix
- Figure 3. Comparing score of feature importance analysis results
- Figure 4. Confusion Metrix of DT
- Figure 5. Confusion Metrix of LR
- Figure 6. Confusion Metrix of RF
7. 結論:
特徴量重要度分析により、Factor 26(圧力解放関連)がポロシティ欠陥に最も寄与する因子であることが結論付けられた。アルゴリズムとしては、決定木(DT)が少数派クラスの分類性能(G-Mean値)を考慮した場合に最良の予測結果を示し、91.18%の精度を達成した。しかし、データセット内のNGデータの割合が極端に低いという不均衡問題は、今後の研究で最適化される必要がある。また、最も堅牢な予測モデルを構築するためには、現場の専門家(SME)との継続的な検証が不可欠である。
8. 参考文献:
- 論文に記載されている参考文献リスト(Aliyan E. et al., 2020 から Zhang Zhongju, and Pengzhu Zhang, 2015 まで)は、元の学術論文をご参照ください。
結論と次のステップ
この研究は、ダイカスト製造における品質向上、欠陥削減、そして生産最適化に向けた、データ駆動型のアプローチの価値あるロードマップを提供します。
CASTMANは、最先端の業界研究を応用し、お客様の最も困難な技術的課題を解決することに尽力しています。この論文で議論されている課題が貴社の目標と一致する場合、ぜひ弊社のエンジニアリングチームにご連絡ください。これらの高度な原則を貴社の研究開発にどのように適用できるか、ご相談させていただきます。
専門家によるQ&A:
- Q1: この研究でポロシティ欠陥に最も影響を与えたプロセスパラメータは何ですか?
- A1: 本研究のTable 2およびFigure 3に示された特徴量重要度分析に基づくと、「Factor 26(圧力解放関連の因子)」がスコア0.053で最も影響の大きいパラメータでした。
- Q2: なぜ決定木(DT)モデルが、より全体精度が高いロジスティック回帰(LR)やランダムフォレスト(RF)よりも優れていると結論付けられたのですか?
- A2: LRおよびRFモデルは高い精度(95.85%)を示しましたが、Table 3によるとG-mean値が0.00であり、Figure 5とFigure 6が示すように、希少な欠陥ケースを一つも予測できませんでした。一方、DTモデルはG-mean値が0.28であり、良品と欠陥品の両方を予測できた唯一のモデルであったため、欠陥検出という実用的な観点から優れていると結論付けられました。
- Q3: この研究で使用されたモデルの欠陥予測精度はどのくらいでしたか?
- A3: 論文の本文(page 6)によると、決定木(DT)アルゴリズムは91.18%の精度を達成しました。ロジスティック回帰(LR)とランダムフォレスト(RF)は95.85%とより高い精度でしたが、これらは実際の欠陥を予測することができませんでした。この結果は、Figure 4-6の混同行列からも裏付けられています。
- Q4: この研究アプローチを実用化する上での課題や今後の検討事項は何ですか?
- A4: 結論部で述べられている通り、2つの主要な課題があります。第一に、データセットが非常に不均衡(NGデータの割合が極端に低い)であるため、この点をレビューし最適化する必要があります。第二に、堅牢な予測モデルを構築するためには、現場の生産結果を基に専門家(SME)と継続的に検証作業を行うことが不可欠です。
著作権
- この資料は、Pavee Siriruk氏およびTitiwetaya Yaikratok氏による論文「Factors Analysis and Prediction in Die-casting Process for Defects Reduction」を分析したものです。
- 論文の出典: Proceedings of the International Conference on Industrial Engineering and Operations Management, Istanbul, Turkey, March 7-10, 2022.
- この資料は情報提供のみを目的としています。無断での商業利用は禁じられています。
- Copyright © 2025 CASTMAN. All rights reserved.