本要約の内容は、「Athens Journal of Sciences」によって発行された論文「Quality Testing in Aluminum Die-Casting – A Novel Approach Using Acoustic Data in Neural Networks」に基づいています。 1. 概要: 2. 抄録 (Abstract): アルミニウムダイカストの品質管理には様々なプロセスが用いられる。例えば、部品の密度測定、X線画像やCT(コンピュータ断層撮影)画像の解析などがある。これらの一般的なプロセスはいずれも実用的な結果をもたらす。しかし、その処理時間やハードウェアコストのため、インライン品質管理に適したプロセスがないという問題がある。そこで本稿では、音響サンプルを用いた高速かつ低コストな品質管理プロセスのコンセプトを提案する。240個のアルミニウム鋳造品の音響サンプルを記録し、X線画像を用いて品質を確認した。全ての部品は、欠陥のない「良品(good)」、空気混入(「ブローホール, blowholes」)のある「中程度(medium)」、湯境(cold flow marks)のある「不良品(poor)」のカテゴリに分類された。生成された音響サンプルの処理のために、畳み込みニューラルネットワーク(Convolutional Neuronal Network)が開発された。ニューラルネットワークのトレーニングは、完全な音響サンプルとセグメント化された音響サンプル(「ウィンドウイング, windowing」)の両方を用いて行われた。生成されたモデルは、120個の音響サンプルからなるテストデータセットで評価された。結果は非常に有望であり、両モデルはそれぞれ95%と87%の精度(accuracy)を示した。この結果は、ニューラルネットワークを利用することで、新しい音響品質管理プロセスが実現可能であることを示している。モデルはほとんどのアルミニウム鋳造品を正しいカテゴリに分類した。 3. 序論 (Introduction): 迅速かつコスト効率の高い品質管理は、製造業において中心的な役割を果たす。現代的な手法、特に人工知能やニューラルネットワークなどの革新的技術は、そのようなプロセスを設計するための全く新しい可能性を開く。アルミニウム鋳造品の品質保証に頻繁に用いられる手法には、CTやX線検査がある。これらは、部品の画像を撮影し、空気溜まり(「ブローホール」)や亀裂(cracks)などの欠陥を検出する。しかし、CTスキャンなどは、一般的なプロセス時間(1個あたり約30秒)と比較して記録時間(1個あたり20~30分!)が著しく長く、意味のあるインライン工程管理(inline process control)には現実的ではない。本研究では、ニューラルネットワークを用いた音響データ処理が、高速、低コスト、かつインライン対応可能な品質保証方法として実行可能かどうかを検討する。その根底にある仮説は、製造上の欠陥が鋳造品の密度を変化させ、それによって音響特性(音と周波数)が変化し、これをニューラルネットワークが識別できるというものである。 4. 研究の要約 (Summary of the study): 研究テーマの背景 (Background of the research topic): アルミニウムダイカストの品質管理は、密度測定、X線イメージング、CTなどの手法に依存している。これらの手法は効果的であるが、速度とコストの面で限界があり、生産中のインライン品質管理への適用を妨げている。 先行研究の状況 (Status of previous research): 音声、音楽、パターン認識などの応用分野において、ニューラルネットワークを用いたオーディオデータ処理は大きな進歩を遂げている。技術には、生オーディオデータの処理や、スペクトログラム(spectrograms)やメル周波数ケプストラム係数(Mel
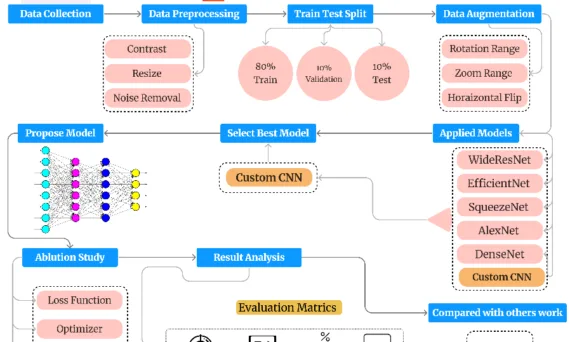
この紹介資料は、「IEOM Society International」によって発行された論文「Improving Die-Casting Part Classification using Transfer Learning with Deep Convolutional Neural Networks」に基づいています。 1. 概要: 2. 抄録: 製品品質は、企業の競争優位性と消費者の要求を決定するため、今日の製造プロセスにおいて極めて重要な要素です。問題は、従来の技術や品質管理方法が現在の環境では効果が薄れてきており、その結果、先進技術への需要が高まっていることにあります。本研究は、ダイカスト部品の欠陥を特定する上で深層学習(DL)技術の有効性を設計し評価することを目的としています。データセットは前処理され、モデルの過学習リスクを軽減し汎化能力を向上させるためにデータ拡張技術が採用されています。5つの事前学習済みDLモデル(AlexNet、DenseNet、EfficientNet、SqueezeNet、WideResNet)が、提案されたカスタム畳み込みニューラルネットワーク(CNN)モデルと比較されました。評価は、精度(precision)、再現率(recall)、正解率(accuracy)、F1スコアを含む性能指標を用いて行われました。提案されたカスタムCNNモデルは98.08%の最高正解率を達成し、他のすべてのモデルを上回りました。次に高い正解率はSqueezeNetモデルの97.70%でした。結果は、提案されたDLベースのアプローチ、特にカスタムCNNモデルが、品質管理プロセスを大幅に改善し、不良品の製造を低減できることを示しています。 3. 緒言: あらゆる製造会社の主な目標は、鋳造プロセスにおける欠陥や不良を排除することにより、グローバル市場での収益性と競争力を維持することです(Gupta et al. 2023)。鋳造は、モーター、発電機、コンプレッサーなどの産業機械や、ストーブ、家具、キッチン用品などの家庭用品を含む様々な用途で採用される、非常に適応性の高いプロセスです。ダイカストは、特に航空宇宙、自動車、電子機器、現代製造業において、複雑な金属部品を製造する上で不可欠です(Duan et al. 2023)。 欠陥製品は、脆弱で信頼性の低い構造をもたらし、重大なリスクを引き起こす可能性があります。すべての鋳造製品は、顧客の期待を満たし、品質基準を維持するために、出荷前に包括的な検査が必要です(Oh et al. 2020)。鋳造会社は、欠陥製品が納入された場合、収益損失や潜在的な注文キャンセルの重大なリスクに直面します。このような問題は、会社の評判を損ない、顧客関係を悪化させ、長期的に業績に悪影響を与える可能性があります。従来、ダイカストの欠陥検出は、コストがかかり、時間がかかり、人的ミスを起こしやすい手動検査技術に依存してきました(Yousef & Sata 2023)。産業プロセスの自動化とデジタル化に伴い、より効率的で精密な欠陥検出システムへの需要が高まっています。転移学習は、限られたデータという課題に対処するための効果的な解決策であることが示されており、事前学習済みモデルを特定のタスクに適応させることができます。DL手法は、検査プロセスを自動化することにより、欠陥検出の速度と精度を大幅に向上させ、製品品質の向上と生産コストの削減をもたらします。本研究は、ダイカストにおける欠陥検出を改善し、それによって製造プロセスの最適化、廃棄物の削減、およびより高い生産品質の確保を促進することを目的としています。 4. 研究の概要: 研究テーマの背景: 製品品質は製造業において最も重要です。ダイカストは複雑な部品に不可欠なプロセスですが、欠陥は故障につながる可能性があります。従来の検査方法は現代の要求には不十分であり、自動化され、正確で効率的な欠陥検出システムの必要性が生じています。深層学習(DL)と転移学習は有望な解決策を提供します。 先行研究の状況: 研究者たちは、鋳造欠陥検査のために様々な人工知能(AI)およびDL技術を適用してきました。研究には、鋳鉄部品に対する深層学習の使用(Wang & Jing, 2024)、小規模データセットを用いたCNN(Dong et al., 2020)、限られたデータでのEfficientNetB7などのアルゴリズム評価(Pranav et al., 2023)、鋼材欠陥用の軽量ネットワーク開発(Lal et al., 2023)、ポンプインペラ用CNNの使用(Chigateri et al.,
[Computer-Aided Design & Applications]에서 발행한 [“Predicting Die Cracking in Die-Cast Products Using a Surrogate Model Based on Geometrical Features”] 의 논문 연구 내용을 소개합니다. 1. 概要: 2. 概要または序論 本論文では、製品設計の幾何学的特徴に着目し、ダイカスト製品におけるダイクラックを予測するための代用モデルの開発と応用について探求しています。ダイカストは、複雑な形状の製品を迅速に量産する効率性で知られる工法であり、特に自動車産業においては、車両重量の削減と部品点数の削減に大きく貢献しています。しかし、製品の品質保証と開発リードタイムの短縮は依然として重要な課題であり、製品設計段階における複雑な形状の欠陥予測の困難さによってさらに悪化しています。従来のシミュレーション技術は標準的であるものの、準備と実行に長時間を要するため、より効率的な欠陥予測のためにビッグデータと機械学習を活用する方向へと移行が進んでいます。本研究では、ダイカストにおける喫緊の課題であり、生産の遅延とコストの増大につながるダイクラックの発生を予測するために、Variational Autoencoders (VAE) とニューラルネットワークを用いた新規な代用モデルを導入します。トヨタ自動車株式会社のエンジンブロック部品とトランスアクスルケースを分析することにより、このモデルはダイクラックを高精度に予測する上で有望な結果を示しました。この知見は、製品形状データを活用して早期の欠陥検出を行うことでダイカストプロセスを改善し、製造効率と製品品質を向上させるための新たな方向性を示唆しています。 3. 研究背景: 研究トピックの背景: ダイカストは、複雑な形状の製品を高速で量産できるため、工業生産、特に自動車産業で広く利用されており、近年、車両の軽量化と製品の部品点数削減の観点から改めて注目されています。工業製品としての高い競争力を確保するためには、市場のトレンドを正確に反映した製品をタイムリーに供給する必要があり、そのためには製品開発のリードタイムを短縮することが重要です。自動車産業における製品開発プロセスは通常、「製品設計」から「金型設計」、「生産性シミュレーション」、「工程設計」、「機能評価」、そして最終的に「量産」という流れを辿ります。このプロセスは一方通行ではなく反復的であり、各段階のサイクルを繰り返すことで製品設計の完成度を高めます。しかし、プロセスが進むにつれて仕様はより複雑になり、修正や手戻りが増加する傾向があります。したがって、可能な限り手戻りを少なくしてプロセスを進めることが重要です。手戻りの回数を減らし、製品開発リードタイムを短縮するためには、製品形状だけでなく、材料選定や製造計画の策定も製品設計の初期段階から考慮した高品質な設計を実現することが不可欠です。Pahl and Beitz [2] が述べているベストプラクティスによれば、最終製品が必要な基準をすべて満たすように、製品設計はこれらの側面を包含する必要があります。しかし、初期設計段階で複雑な形状の製品に対して正確な予測を行うことはしばしば困難であり、これらの要因が設計プロセスの初期段階で適切に考慮されない場合、手戻りにつながる可能性があります。このような背景から、「事前予測」とは、初期設計段階における潜在的な欠陥の予備的な見積もりを指します。これは、後続の設計段階で実施される詳細な予測とは異なります。正確な事前予測は、複雑な形状の製品にとっては困難であり、この段階での不正確さは手戻りの必要性を招く可能性があります。 既存研究の現状: この問題を解決する一つの方法は、製品を製造する前にシミュレーションを用いて機能を予測し、事前に問題を修正することです。実際、シミュレーション技術は広く採用されており、工業製品の開発プロセスにおける標準的な技術となっています [3, 4, 5, 6]。鋳造シミュレーションにおいては、従来は溶融金属の流体解析に焦点が当てられていましたが、現在では背圧の影響を検証し、スパウトでの跳ね返り挙動に関する精度を向上させるために、周囲の空気圧縮挙動の計算も組み込まれるなど、精度向上の取り組みも行われています [7]。さらに、量子コンピュータを用いて計算時間を短縮し、検討サイクルを高速化する研究も行われています [8]。しかし、これらの技術が実用化されたとしても、シミュレーションを実行するためには、製造用の金型モデル情報を作成する必要があります。修正を含めると、1回のシミュレーションを完了するのに数日を要します。したがって、シミュレーションの精度向上と時間短縮が実現されたとしても、シミュレーションを利用した予備検討時間の長期化という問題の一部しか解決されず、製品開発の初期段階における容易な欠陥予測という課題は未解決のまま残されています。 研究の必要性: シミュレーション技術の進歩には限界があるため、過去に製造された製品の欠陥発生情報や蓄積されたシミュレーション結果から得られたビッグデータを分析・活用し、パターン認識を現在および将来の生産性予測の付加価値に転換する代替アプローチが積極的に追求されています [9]。これらの取り組みの中でも、代用モデルとして知られる技術は、詳細なシミュレーションを実行する代わりに、既知のデータから得られたパターンを用いて予測を行う機械学習などの手法を採用しており、計算コストと事前準備情報の削減を可能にするため、注目を集めています。例えば、Amir Pouya は、ニューラルネットワークを用いてレーザー溶接加工パラメータを学習することにより、溶融プールの断面温度分布を予測できるモデルを提案しました [10]。さらに、Andres らは、低計算コストで航空機ブレードの断面形状を推定する手段として
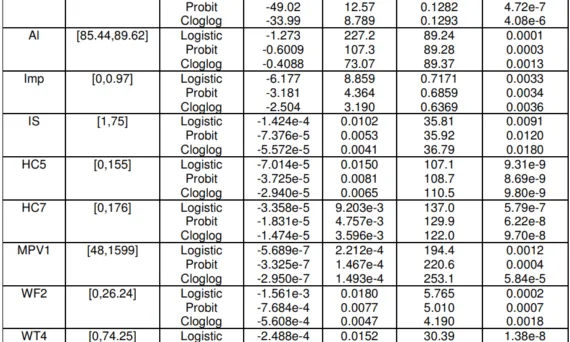
This paper introduction was written based on the ‘INDUSTRY 4.0 FOUNDRY DATA MANAGEMENT AND SUPERVISED MACHINE LEARNING IN LOW-PRESSURE DIE CASTING QUALITY IMPROVEMENT’ published by ‘International Journal of Metalcasting’. 1. 概要: 2. 概要または序論 低圧ダイカスト(LPDC)は、高性能、高精度なアルミニウム合金自動車ホイール鋳物の製造に広く使用されており、気孔率欠陥などの欠陥は許容されません。LPDC部品の品質は、鋳造プロセス条件に大きく影響されます。ガスや収縮気孔率などの困難な欠陥に対する部品品質を向上させるためには、プロセス変数を最適化する必要があります。これを行うには、プロセス変数の測定値を欠陥の発生率と照らし合わせて調査する必要があります。本論文では、Industry 4.0クラウドベースのシステムを使用してデータを抽出します。これらのデータを用いて、実際の鋳造アルミニウムLPDCプロセスで欠陥を予測する条件を特定するために、教師あり機械学習分類モデルが提案されています。このプロセスの欠陥率は小さく、潜在的なプロセス測定変数が多数存在するため、根本原因の分析は困難です。XGBoost分類アルゴリズムに基づくモデルを使用して、プロセス条件と欠陥のあるホイールリムの生成との間の複雑な関係をマッピングしました。データは、特定のLPDCマシンとダイモールドから、3シフト、6日間連続で収集されました。気孔率欠陥の発生率は、かなり小さなサンプル(1077個のホイール)から収集された13のプロセス変数からの36の特徴量を使用して予測でき、非常に偏っており(欠陥品62個)、良品で87%の精度、気孔率欠陥のある部品で74%の精度でした。この研究は、欠陥を減らすための新製品の量産前段階でのプロセスパラメータ調整を支援する上で役立ちました。 3. 研究背景: 研究トピックの背景: 低圧ダイカスト(LPDC)は、高性能、高精度、大量生産が求められる金属鋳造部品、特に自動車産業におけるアルミニウム合金ホイールリムの製造において広く利用されています。気孔率の不連続性は、LPDCアルミニウム製品で最も頻繁に見られる欠陥の一つです。これらは回避が難しく、部品の完全性と性能を損なう可能性があります。したがって、気孔率欠陥の原因と防止は品質管理において重要な考慮事項であり、部品品質を向上させるためにプロセス変数を最適化する要求を生み出しています。気孔率欠陥の原因は、金属組成、水素含有量、鋳造圧力、温度、指向性凝固速度を得るための金型熱管理など、さまざまな要因に起因する可能性があります。このような鋳造欠陥が発生した場合、正確な根本原因を診断し、適切なプロセスパラメータ変更を行うことはしばしば困難です。気孔率欠陥を引き起こす可能性のあるプロセス設定と逸脱を監視および分析する手段が必要です。Industry 4.0品質管理システムは、すべてのプロセス測定ポイントから記録されたデータを、検査結果を含む個々の部品に関連付けることができます。これにより、機械学習分類器アルゴリズムを利用して、プロセス欠陥を引き起こすプロセス設定の組み合わせを特定できます。これらは、プロセス制御の調整に役立てることができます。 既存研究の現状: LPDC生産は歴史的に高い不良率を示しており、通常、すべての生産部品は気孔率欠陥についてX線検査されています。この研究は気孔率欠陥を予測するのに役立ちますが、検査のためのX線装置に取って代わることはできません。しかし、気孔率欠陥の原因を定量化するのに役立ちます。典型的な鋳造工場では、数百種類のモデルと、毎年数十種類の新製品モデルが導入されます。量産前のプロセス設定を迅速に調整することが重要です。最初のセクションでは、LPDC鋳造工場の生産運転中に欠陥の原因を特定する際の課題が提示され、その後、関連研究について議論します。「Industry 4.0 Foundry Data Collection」では、鋳造工場全体で部品と関連データをデジタルタイムスタンプで追跡するためのIndustry 4.0データ収集システムが提示されています。「LPDC Porosity Defect Prediction」では、監視された鋳造欠陥について議論します。次に、「Classification Algorithm Model」では、気孔率欠陥が発生するプロセス条件を分類する統計的機械学習モデルが提示されています。 研究の必要性: 工場データを使用して欠陥部品の発生を予測する機械学習モデルを構築することは、いくつかの理由から困難です。潜在的な因果関係の要因の数が膨大であること、これらのプロセスデータをすべて収集するために計測することが困難な場合があります。また、時系列データの特徴を特定する必要があります。これには、高低シフト、変動が大きすぎる、またはデータ対時間のジャンプなどが含まれます。欠陥の原因に関連付けられる可能性のある特徴が検討されます。さらに、収集されたプロセスデータは、実際に生産されている部品に関連付けられている必要があります。これにより、これらのプロセス条件を部品の合格または不合格の指標に関連付けることができます。プロセスデータを収集するだけでは不十分であり、プロセスデータは部品にタグ付けする必要があります。これは、どのプロセスデータをどの部品に関連付けるかを知るために、部品を鋳造工場全体で追跡する必要があることを意味します。これは、スマートファウンドリの重要なIndustry 4.0の課題の1つです。鋳造工場は過酷な条件下で操業しており、投入材料の流れの開始から最終鋳造部品まで、各部品を追跡およびマークすることは困難です。2番目の課題は、時系列データを機械学習統計分析用の特徴量に前処理することです。完全なデータセットではなく、プロセスエンジニアが理解できるエンジニアリング統計を検討することが有用です。たとえば、時系列の圧力、温度、冷却データを位相に分離し、各位相内の統計量を計算できます。これには、データを充填や凝固などの位相に分離し、位相内の平均や分散などの特徴量を計算することが含まれる場合があります。プロセスエンジニアは、さまざまな位相での平均シフトと変動の大小が歩留まりにどのように影響するかを理解したいと考えています。最後に、特徴量が与えられた場合、これらの特徴量を欠陥率に関連付けるために利用可能な代替分類手法も多数存在します。全体として、機械学習を活用して欠陥の原因と根本原因をより深く理解するための研究機会が存在します。現在の鋳造工場のプロセス制御は、一般的に検査ベースの受入手順です。投入材料、鋳造結果の品質管理、およびプロセス制御は、指定された制限内でコンプライアンスについて検査または監視されます。部品の欠陥は、気孔率ボイドの存在に関するX線画像の目視検査によって定義されます。操業上の問題は、入力が許容範囲外になった場合に定義されます。この現状では、欠陥制御が困難になっています。第一に、目視検査と手動制御は、かなりの再現性と再現性の測定誤差を伴う可能性があります。また、このアプローチでは、許容範囲内の入力の組み合わせが、気孔率欠陥を発生させることを知らずに許容してしまう可能性があります。プロチャによって導入されたように、ステップバイステップの知識ベースのアプローチを採用して、より高品質な成果を得るために、鋳造プロセスの人工知能とデータ駆動型プロセス制御を構築します。Industry